
Patrick's 데이터 세상
Spark Standalone 실행 본문
반응형
SMALL
1. Spark 디렉토리 안 sbin으로 이동

2. 마스터 실행
sh start-master.sh
2-1. localhost:8080에서 마스터 실행 여부와 url 확인

3. 슬레이브 노드 실행
실행한 마스터에 워커를 등록한다.
# sh로 실행이 안되어 bash로 실행
# -m는 메모리 지정, -c는 코어 지정
bash start-slave.sh spark://park-VirtualBox:7077 -m 1024M -c 1
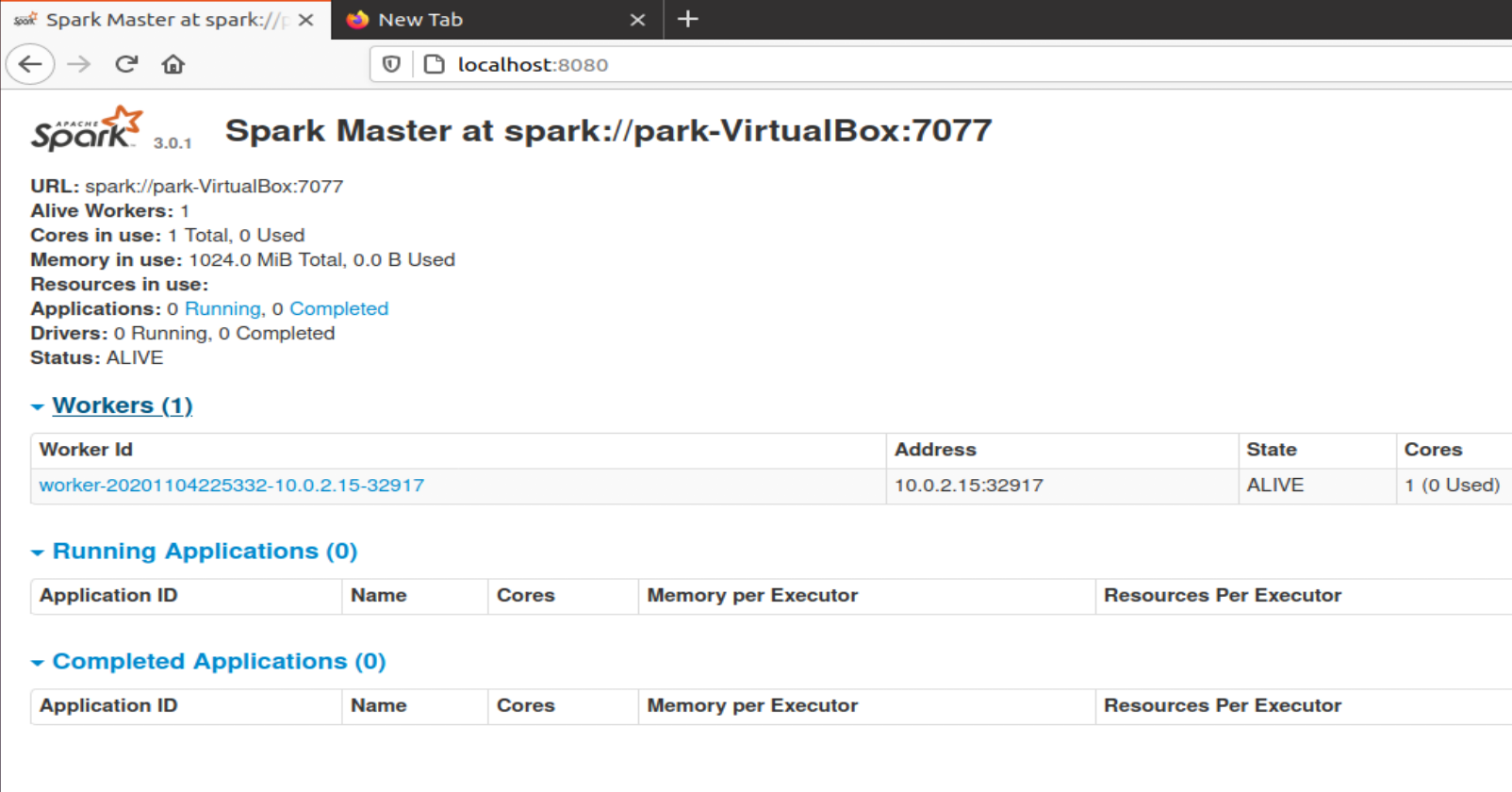
워커가 1개 달려있는 것을 확인할 수 있다.
하나의 vm에서 하나의 쓰레드가 생긴 것이고 Spark 어플리케이션 실행 시 병렬 처리된다.
반응형
LIST
'Data Analysis > Spark' 카테고리의 다른 글
| Spark RDD 실습 (0) | 2020.11.05 |
|---|---|
| Spark RDD (0) | 2020.11.04 |
| Apache Spark 기본 이론 (0) | 2020.10.26 |
'Data Analysis/Spark' Related Articles
more



Comments