
Patrick's 데이터 세상
논문 정리 - Learning Loss for Active Learning 본문
https://arxiv.org/abs/1905.03677v1
Learning Loss for Active Learning
The performance of deep neural networks improves with more annotated data. The problem is that the budget for annotation is limited. One solution to this is active learning, where a model asks human to annotate data that it perceived as uncertain. A variet
arxiv.org
제목
Learning Loss for Active Learning
저자
Donggeun Yoo, In So Kweon
소개
최근 deep network의 성능은 train data의 크기에 비해 아직 포화 상태가 아니다.
따라서 semi-supervised learning, unsupervisored learning 학습 방법이 weak-labeled data, unlabel 된 대규모 데이터와 함께 주목받고 있다.
그러나 고정된 양의 데이터가 주어지면 semi-supervise 또는 unsupervised learning의 성능은 여전히 full-supervised learning에 제한된다.
또한, 주석 비용은 대상 작업에 따라 크게 다르다.
예산은 한정되어있고, 자연 이미지 영역의 레이블 annotation은 비교적 저렴하지만 bio-medical 이미지 영역에서는 각 분야에 전문의를 통한 주석이 필요해 훨씬 값비싸다.
이진 분류에서 사후 확률이 0.5에 가장 가까운 데이터 포인트를 선택하고 주석을 달고 훈련 데이터에 추가한다.
active learning의 핵심 아이디어는 가장 유익한 데이터 포인트가 무작위로 선택된 데이터 포인트보다 모델 개선에 더 유리하다는 것이다.
label이 지정되지 않은 data pool이 주어지면 선택 기준에 따라 세 가지 주요 접근 방식이 있습니다.
불확실성 기반 접근 방식(uncertainty-based apporoach), 다양성 기반 접근 방식(diversity-based approach), 예상 모델 변경(expected model change approach)
불확실성 접근 방식은 불확실 데이터 포인트를 선택하기 위해 불확싱성의 양을 정의, 측정한다.
가장 간단한 방법은 클래스 사후 확률을 사용하여 불확실성을 정의하는 것.
여러 모델을 훈련하고 committe의 여러 예측 간의 합의를 측정하지만 committee를 구성하는 것은 대규모 학습된 최근의 deep network에 너무 많은 비용이 든다.
다양성 접근법은 전체를 나타내는 다양한 데이터 포인트를 선택.
예상 모델 변경은 레이블을 알고 있는 경우 현재 모델 매개변수 또는 출력에 가장 큰 변경을 데이터 포인트를 선택.
소규모 모델에서는 성공적이었지만 최근 deep network에서는 계산적으로 비실용적이다.

위 모델에 연결된 loss prediction module은 label이 없는 입력에서 loss 값을 예측한다.
label이 지정되지 않은 pool의 모든 data point는 loss prediction module에 의해 evaluate 된다.
top-K개의 예측 손실이 있는 데이터 포인트에 레이블이 지정되고 레이블이 지정된 훈련 세트에 추가된다.
active learning은 작업이 무엇인지, 작업이 얼마나 많은지, 아키텍처가 얼마나 복잡한지에 관계없이 single loss를 최소화하여 deep network를 학습한다.
만일 우리가 데이터 포인트의 loss 값을 예측할 수 있다면, 높은 loss로 예상되는 데이터 포인트를 선택 할 수 있다.
선택한 데이터 포인트는 현재 모델의 더 많은 정보를 제공한다.
이 시나리오를 실현하기 위해 'loss prediction module'을 deep network에 연결하고 입력 데이터 포인트의 loss를 예측하는 모듈을 학습한다.
deep network를 사용하는 모든 작업에 이 방법을 적용할 수 있다.
방법

손실 예측 모듈은 위 그림처럼 대상 모델에 첨부된다.
목표 모델은 목표 태스크를
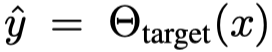
로 수행하는 반면,
손실 예측 모델은
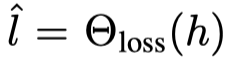
로 예측한다.
h는 세타 타깃의 여러 은닉층에서 추출한 x의 특징 세트다.
대부분의 실제 학습 문제에서 unlabed data
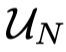
의 large pool을 한 번 수집할 수 있다.(N : 데이터 포인트 개수)
Loss Prediction Module
손실 예측 모듈은 대상 모델에 정의된 손실을 모방하는 방법을 배우기 때문에 작업에 구애받지 않는 active learning의 핵심이다.
active learning을 위한 작업별 불확실성을 정의하는 엔지니어링 비용을 최소화하는 것을 목표로 한다.
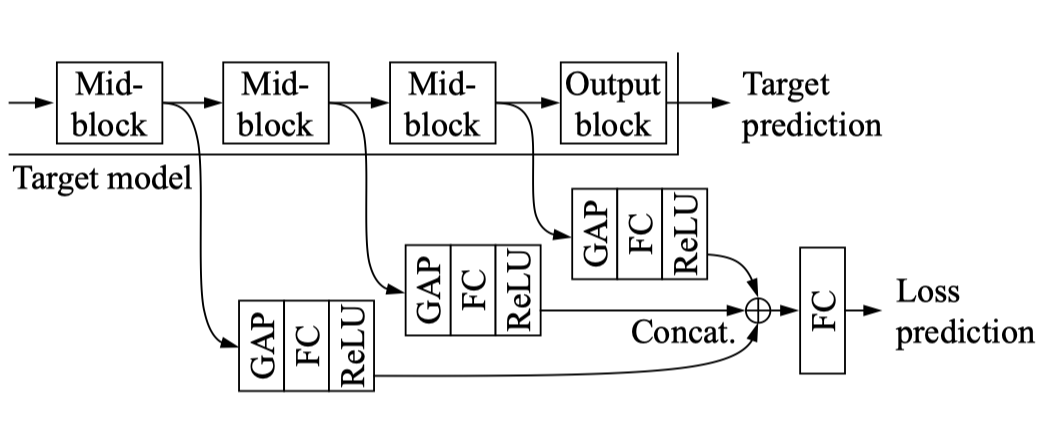
대상 모델의 mid-level block 사이에서 추출되는 입력으로 다층 피쳐 맵 h를 취한다.
이러한 다중 연결을 통해 손실 예측 모듈은 손실 예측에 유용한 계층 간에 필요한 정보를 선택할 수 있다.
각 feature map은 GAP(Global Average Pooling layer) 계층과 FC(Fully-connected layer)을 통해 고정 차원 피처 벡터로 축소된다.
그 후 다음 모든 기능이 연결되고, 다른 완전 연결 계층을 통과하여 예측 손실로 스칼라 값
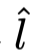
이 생성된다.
정리
Active Learning에 대한 개념에 대해 공부해보았다.
Supervised Learning을 하기 위한 data label 작업은 많은 공수와 비용이 발생하므로 적절한 Active Learining 사용으로 모델의 효율의 크게 증가할 수 있을 것으로 기대된다.
pytorch 모델로 구현 가능 할 것 같고, 업무 중 huggingface pretrained model에 구현하는 중이다.
참고
https://arxiv.org/abs/1905.03677v1
Learning Loss for Active Learning
The performance of deep neural networks improves with more annotated data. The problem is that the budget for annotation is limited. One solution to this is active learning, where a model asks human to annotate data that it perceived as uncertain. A variet
arxiv.org


