
Patrick's 데이터 세상
Attention Mechanism 본문
Attention
입력 시퀀스를 인코더에서 하나의 고정된 Context Vector로 압축하고 이를 활용하여 디코더에서 출력 시퀀스를 만드는 seq2seq는 여러 문제점이 있습니다.
∙ 하나의 고정된 크기의 벡터에 인코더의 모든 정보를 압축하다 보니 정보 손실이 발생합니다.
∙ RNN의 고질적인 기울기 소실(Vanishing Gradient) 문제가 존재합니다.
위 문제는 입력 문장이 길면 번역 품질이 떨어지는 현상으로 나타납니다.
이를 위한 대안으로 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보완하기 위해 등장한 기법이 Attention입니다.
Attention의 기본 아이디어는 디코더에서 출력 단어를 예측할 때, 매 시점(time step)마다, 인코더에서 전체 입력 문장을 다시 한번 참고한다는 개념입니다.
단, 전체 입력 문장을 다 동일한 비율로 참고하는 것이 아닌 해당 시점에서 예측해야할 단어와 연관 있는 단어에 좀 더 집중하게 됩니다.
👉🏻 Attention Function

어텐션 함수의 구조는 왼쪽 그림과 같습니다.
Attention(Q, K, V) = Attention Value
주어진 쿼리(Query)에 대해 모든 키(Key)와의 유사도를 각각 구합니다.
그 후 유사도를 키와 맵핑된 값(Value)에 반영합니다. 그리고 유사도가 반영된 값(Value)을 모두 더해 리턴합니다. 이것을 어텐션 값(Attention Value)이라고 합니다.
👉🏻 Dot-Product Attention
Attention에는 Dot-Product Attentiion, Scaled Dot-Product Attentiion, Additive Attention, Multi-head Attention 등 다양한 종류가 있는데 이 들은 메커니즘 자체는 유사하지만 수식의 차이가 있습니다.
그중 Dot-Product Attention은 어텐션 구조에서 가장 기본이 되고 수식이 간단합니다.
seq2seq + Attention Model에서의 Q, K, V
∙ Q = Query : t 시점의 디코더 셀에서의 은닉 상태
∙ K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
∙ V = Values : 모든 시점의 인코더 셀의 은닉 상태들
왼쪽 그림은 디코어의 세 번째 LSTM 셀에서 출력 단어를 예측할 때, 어텐션 매커니즘의 구조입니다.
디코터에서 1, 2번 LSTM 셀에서 어텐션 매커니즘으로 'je', 'suis'를 예측하고 디코더 3번 LSTM 셀에서 출력 단어를 예측할 때, 인코더의 모든 입력 단어들의 정보를 다시 한번 참고해야 하는데 이때 인코더의 소프트맥스 함수가 적용됩니다.
소프트맥스 함수를 통해 'I', 'am', 'a', 'student' 각 단어들이 출력 단어를 예측할 때 얼마나 연관이 있는지를 판단합니다.
연관이 클수록 크기가 커지고 초록 삼각형에서 이것을 하나의 정보로 담아 디코더에서 받아들입니다.
이 과정을 통해 디코더에서는 출력 단어를더 정확하게 예측할 확률이 높아집니다.
→ 계산 과정
1) 어텐션 스코어(Attention Score)를 구한다.
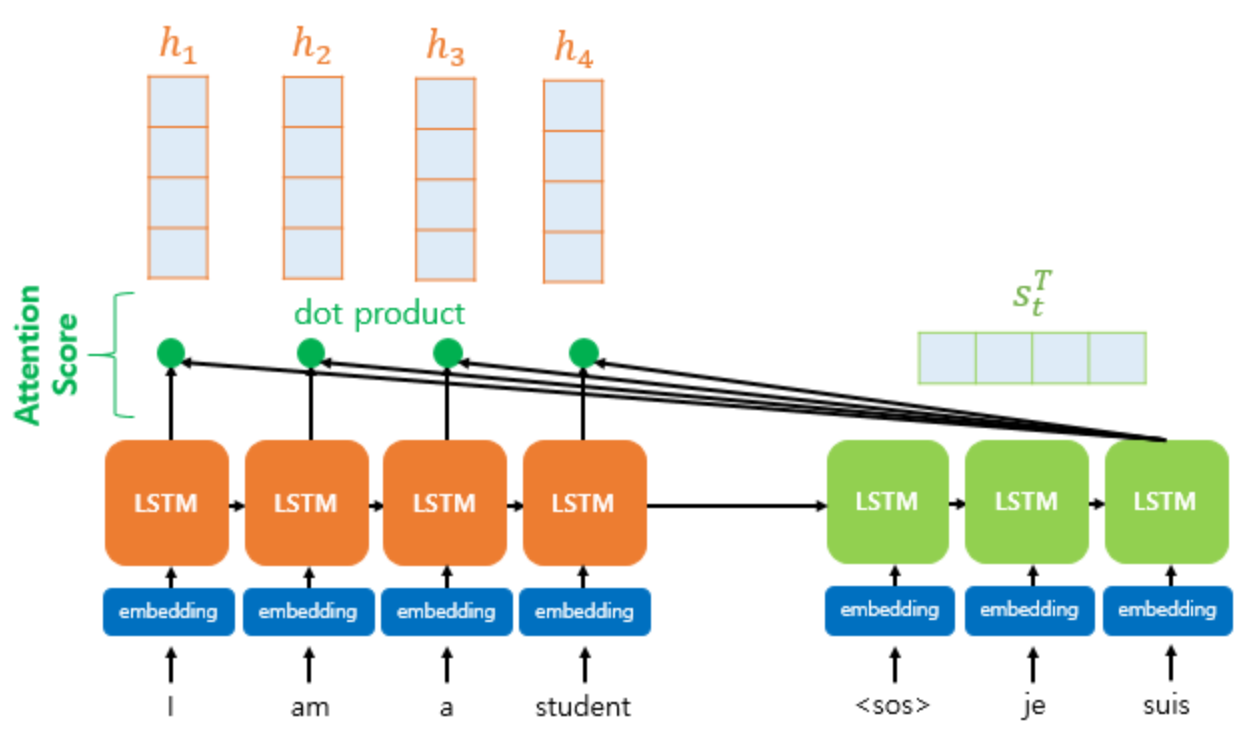
인코더 시점(time step)이 각각 1, 2,...,N이면 인코더의 은닉 상태(hidden state)는 각각 h1, h2,...,hN이 되고 디코더의 현재 시점(time step) t에서의 은닉 상태(hidden state)는 st입니다. 인코더의 은닉 상태와 디코더의 은닉 상태는 차원이 4로 동일합니다.
시점 t에서 출력 단어를 예측하기 위해서 디코더의 셀은 이전 시점 t-1의 은닉 상태와 이전 시점 t-1에 나온 출력 단어 두 개를 입력값으로 받습니다. 여기에 어텐션 메커니즘에서는 출력 단어 예측에 어텐션 값(Attention Value)까지 필요합니다.
t번째 단어를 예측하기 위한 어텐션 값이 at일 때, at를 구하기 위해서는 어텐션 스코어(Attention Score)를 구해야합니다.
어텐션 스코어는 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉 상태 st와 얼마나 유사한지를 판단하는 스코어 스칼라 값입니다.


닷-프로덕트 어텐션에서 이 스코어 값을 구하기 위해 st를 전치(transpose)하고 각 은닉 상태에 내적(dot-product)을 수행합니다. 즉, 모든 어텐션 스코어 값은 스칼라입니다.
왼쪽 그림은 st와 인코더의 i번째 은닉 상태의 어텐션 스코어의 계산법입니다.
st와 인코더의 모든 은닉 상태의 어텐션 스코어 모음집을 e의 t제곱이라고 할 때, e의 제곱은 아래와 같습니다.

2) 소프트맥스(softmax) 함수를 취해 어텐션 분포(Attention Distribution)를 구한다.
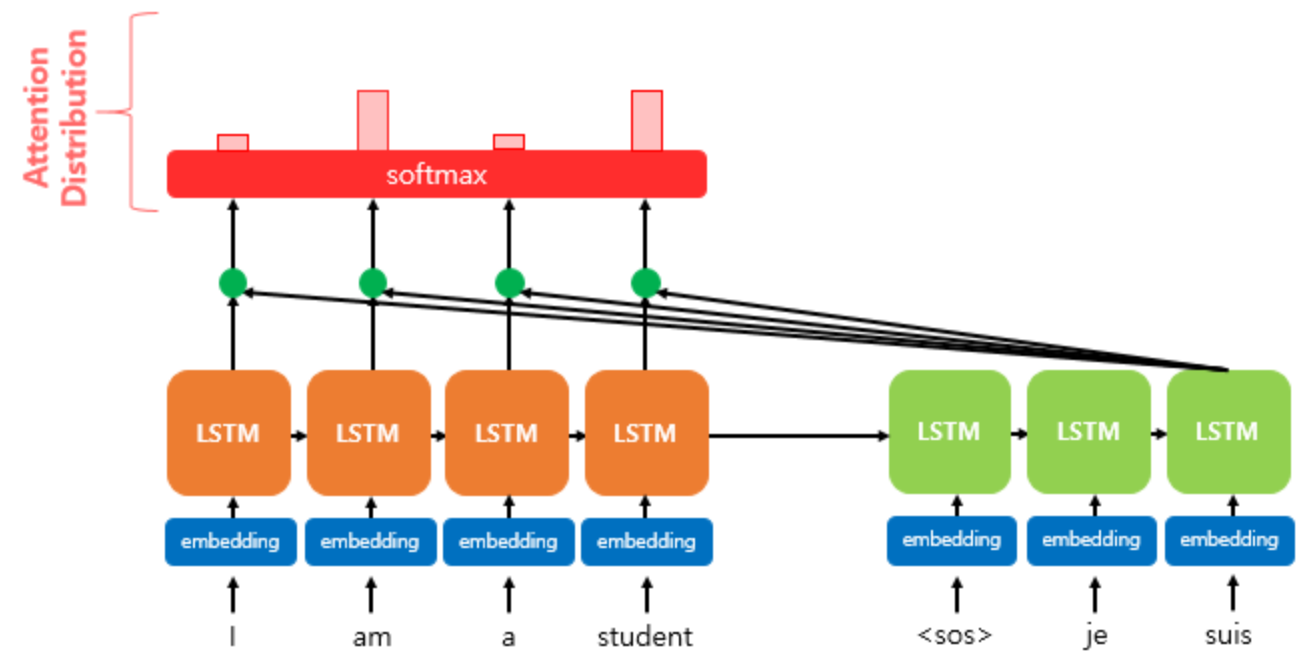
e의 t제곱에 소프트맥스 함수를 적용하여, 모든 값으르 합하면 1이 되는 확률 분포를 얻는데, 이것을 어텐션 분포(Attention Distribution)이고 각각의 값은 어텐션 가중치(Attention Weight)라고 합니다.
'i', 'am', 'a', 'student' 입력에 소프트맥스를 적용하여 얻은 어텐션 가중치 출력값이 각각 0.1, 0.4, 0.1, 0.4이면 이들의 합은 1입니다. 왼쪽 빨간 직사각형은 각 인코더의 은닉 상태에서 어텐션 가중치의 크기를 나타냈습니다.

디코더의 시점 t에서 어텐션 가중치의 모음값인 어텐션 분포 수식입니다.
3) 각 인코더의 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값(Attention Value)을 구한다.

지금까지의 정보들을 하나로 합칩니다.
어텐션의 최종 결과값을 얻기 위해 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고, 모두 더합니다. 이를 가중합(Weighted Sum)이라고 합니다.

왼쪽 수식은 어텐션의 최종 결과, 어텐션 함수의 출력값의 어텐션 값(Attention Value) at입니다.
이러한 어텐션 값 at는 종종 인코더의 문맥을 포함하고 있다고 하여, 컨텍스트 벡터(Context Vector) 라고 불립니다.
4) 어텐션 값과 디코더의 t 시점의 은닉 상태와 연결(Concatenate)한다.

어텐션 함수의 최종값인 어텐션 값 at를 구하고 나면 어텐션 메커니즘은 at를 st와 결합하여 하나의 벡터로 만드는 작업을 수행하고 이를 vt라고 합니다.
어텐션 메커니즘의 핵심 개념은 이 vt를 y hat 예측 연산의 입력으로 사용되어 인코더로부터 얻은 정보를 활용하여 좀 더 잘 예측하게 됩니다.
5) 출력층 연산이 되는 s를 계산합니다.

vt를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 추가합니다. 가중치 행렬과 곱한 후에 하이퍼볼릭탄젠트 함수를 지나게 하여 출력층 연산을 위한 입력으로 새로운 벡터 s~t를 얻습니다.

왼쪽은 위 그림의 수식입니다.
Wc는 학습 가능한 가중치 행렬, bc는 편향입니다.
6) s~t를 출력층의 입력으로 사용합니다.

s~t를 출력층의 입력으로 사용하여 예측 벡터를 얻습니다.
👉🏻 Bahdanau Attention
앞에서 본 닷 프로덕트 어텐션보다 좀 더 복잡하게 설계된 어텐션 메커니즘입니다.
Attention(Q, K, V) = Attention Value
t = 어텐션 메커니즘이 수행되는 디코더 셀의 현재 시점을 의미.
Q = Query : t-1 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
닷 프로덕트 어텐션은 Query가 디코더 셀의 t 시점 은닉 상태지만 바다나우 어텐션의 Query는 디코더 셀의 t-1 시점의 은닉 상태입니다.

t-1 시점의 은닉 상태 st-1를 사용하고 어텐션 스코어 함수. 즉, st-1과 인도커의 i번째 은닉 상태의 어텐션 스코어 계산 방법입니다.
출처
https://arxiv.org/abs/1409.0473
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
15-01 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 출력 …
wikidocs.net
'Deep Learning > 이론' 카테고리의 다른 글
| Transformer - Attention is all you need (0) | 2023.07.25 |
|---|---|
| seq2seq(Sequence-to-Sequence) (0) | 2023.07.22 |
| LSTM(Long Short-Term Memory) (0) | 2022.08.22 |
| RNN(Recurrent Neural Network) (0) | 2022.08.21 |
| Subword Tokenizer (0) | 2021.04.22 |



