
Patrick's 데이터 세상
Word Embedding 이론 본문
단어 임베딩 모델(Word Embedding Model)
자연어를 처리할 때는 텍스트 기반의 모델을 만들어 텍스트를 숫자로 바꾸어 알고리즘으로 처리하게 됩니다.
이렇게 단어를 벡터로 바꾸는 모델을 단어 임베딩 모델(Word Embedding Model)이라고 부릅니다.
단어의 의미를 최대한 담는 벡터를 만들려는 알고리즘이 단어 임베딩 모델이라고 할 수 있습니다.
현대적인 자연어 처리 기법들은 대부분 이 임베딩 모델에 기반을 두고 있습니다.
데이터는 대상의 속성을 표현해놓은 자료입니다.
예를 들어 꽃에 대한 정보가 있는 데이터가 있으면 그 정보는 꽃의 모양, 색깔, 길이 등과 같은 속성이 담겨있을 것입니다. 이 정보를 바탕으로 어떤 꽃인지 판별하는 모델을 만들 수 있습니다.
이렇게 대상의 속성을 표현하는 방식을 언어의 속성 표현(Feature Representation)이라고 부릅니다.
이러한 속성을 표현하는 방법은 크게 두가지로 나뉘는데 하나는 sparse representation, 또 다른 하나는 dense representation이라는 두 가지 방식이 있습니다.
Sparse representation
Sparse representation은 one-hot encoding 방식으로도 불리는데 이 방식은 해당 속성이 가질 수 있는 모든 경우의 수를 각각의 독립적인 차원으로 표현합니다.
마찬가지 방식으로 품사가 ‘강아지’라는 속성을 표현하고 싶다면 품사의 개수만큼의 차원을 갖는 벡터를 총 N개 만들고, 이 속성이 가질 수 있는 경우의 수는 총 N개가 됩니다. 그리고 ‘강아지’에 해당하는 요소만 1로 두고 나머지는 모두 0으로 둡니다.
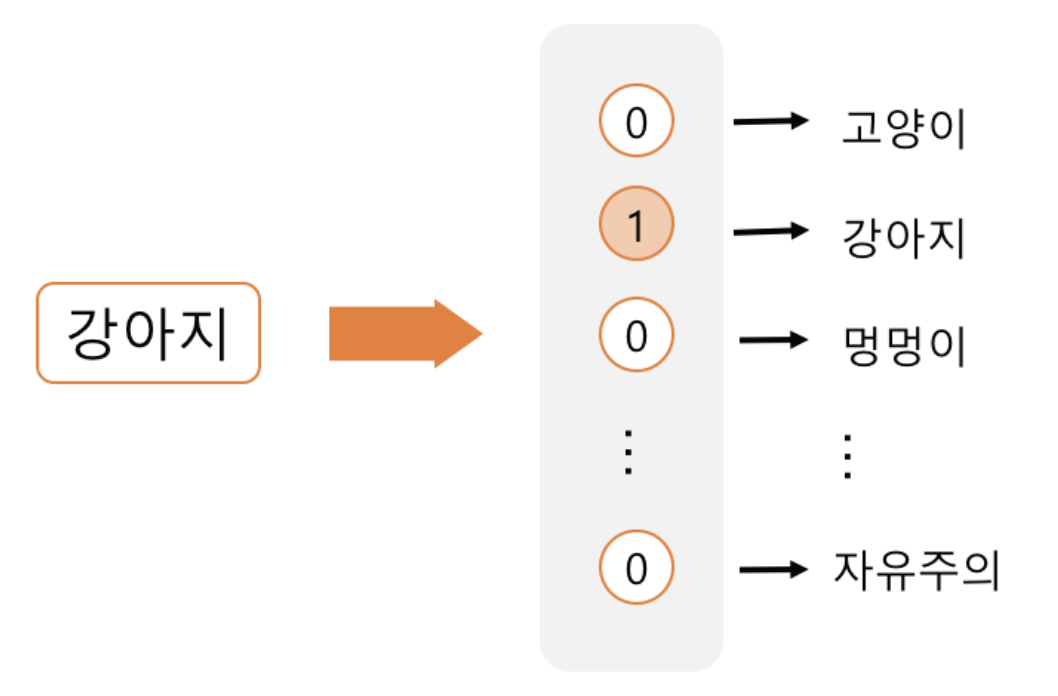
이렇게 one-hot encoding으로 만들어진 표현을 sparse representation이라고도 부릅니다.
one-hot encoding으로 만들어진 벡터는 0이 대부분이기 때문에, sparse 한 벡터가 되는 것입니다.
Sparse representation은 가장 단순하고 예전부터 자주 쓰이던 표현 방식입니다.
Dense representation
Dense representation은 각각의 속성을 독립적인 차원으로 나타내지 않는 대신, 정한 개수의 차원으로 대상을 대응시켜서 표현한다. 표현할 속성을 N차원으로 정하면 그 속성을 N차원 백터에 대응시키는 것입니다.
이 대응을 임베딩(embedding)이라고 하며, 임베딩하는 방식은 머신 러닝을 통해 학습하게 됩니다.

이러한 Dense representation는 여러 차원으로 분산되어 있는 특징도 존재하여 또 다른 말로 distributed representation이라고도 불립니다. Sparse representation에서는 각각의 차원이 각각의 독립적인 정보를 갖고 있지만, Dense representation에서는 하나의 차원이 여러 속성들이 섞인 정보를 들고 있습니다.
즉, 하나의 차원이 하나의 속성을 명시적으로 표현하는 것이 아니라 여러 차원들이 조합되어 나타내고자 하는 속성들을 표현하는 것입니다.
위 그림에서 ‘강아지’란 단어는 [0.16, -0.50, 0.20, -0.11, 0.15]라는 5차원 벡터로 표현됩니다. 이때 각각의 차원은 여러 속성이 섞였기 때문에 어떤 의미를 갖는지는 알 수 없습니다. 다만 ‘강아지’를 표현하는 벡터가 '멍멍이’를 표현하는 벡터와 얼마나 비슷한지 벡터 간의 거리를 통해 알 수 있다.
이러한 관계에서 단어 벡터의 의미가 드러나게 되고 단어 벡터의 값들은 머신 러닝을 통해 학습됩니다.
Dense Representation의 장점
첫번째, dense representation은 적은 차원으로 대상을 표현할 수 있다는 장점이 있습니다. sparse representation으로 대상을 표현하면 보통 차원 수가 엄청나게 높아집니다. 예를 들어 일상적인 텍스트에서 쓰이는 단어의 개수는 몇 천 개에 이르는 단어들을 sparse representation으로 표현하려면 몇 천 차원이 필요합니다. 게다가 이렇게 만들어진 벡터들은 대부분의 값이 0을 갖습니다.
입력 데이터의 차원이 높으면 차원의 저주(curse of dimensionality)라는 문제가 생깁니다. 입력 데이터에 0이 너무 많으면 데이터에서 정보를 뽑아내기 어려워집니다.
따라서 sparse representation을 쓰면 모델의 학습이 어렵고 성능이 떨어지기 쉽습니다.
그에 반해 Dense representation으로 단어를 표현할 때는 보통 20 ~ 200차원 정도를 사용합니다. Sparse representation에서 몇 천 차원이 필요했던 것에 비해 훨씬 적은 차원을 사용하고 0이 거의 없으며 각각의 차원들이 모두 정보를 들고 있으므로 모델이 더 작동하기 쉬워집니다.
두 번째, dense representation은 더 큰 일반화 능력(generalization power)을 갖고 있습니다.
예를 들어 ‘강아지’라는 단어가 학습 데이터셋에 자주 나왔고 ‘멍멍이’라는 단어는 별로 나오지 않았다고 하더라도 dense representation에서 ‘강아지’와 ‘멍멍이’가 서로 비슷한 벡터로 표현이 된다면, ‘강아지’에 대한 정보가 ‘멍멍이’에도 일반화될 수 있습니다. 예컨대 ‘강아지’라는 단어를 입력으로 받고 ‘애완동물’이라는 출력을 하도록 모델이 학습이 된다면, ‘멍멍이’도 비슷한 입력이기 때문에 비슷한 출력이 나올 가능성이 높습니다. 즉, ‘강아지’라는 단어에 대해 배운 지식을 ‘멍멍이’라는 단어에도 적용할 수 있는 것입니다.
출처
dreamgonfly.github.io/blog/word2vec-explained/
쉽게 씌어진 word2vec | Dreamgonfly's blog
텍스트 기반의 모델 만들기는 텍스트를 숫자로 바꾸려는 노력의 연속이다. 텍스트를 숫자로 바꾸어야만 알고리즘에 넣고 계산을 한 후 결과값을 낼 수 있기 때문이다. 텍스트를 숫자로 바꾸는
dreamgonfly.github.io
'Deep Learning > 이론' 카테고리의 다른 글
| 정보 검색 개념 (0) | 2021.02.18 |
|---|---|
| BOW(Bag of Words) (0) | 2020.12.17 |
| 텍스트 분석(Text Analytics) (0) | 2020.12.14 |
| PCA 분석 (0) | 2020.12.02 |
| Word2vec (0) | 2020.11.29 |



