
Patrick's 데이터 세상
텍스트 분석(Text Analytics) 본문
먼저 NLP(National Language Processing)와 텍스트 분석(Text Analytics) 중 NLP는 머신이 인간의 언어를 이해하고 해석하는데 좀 더 중점을 두고 기술이 발전해 왔으며, 텍스트 마이닝(Text Mining)이라고도 불리는 텍스트 분석은 비정형 텍스트에서 의미 있는 정보를 추출하는 것에 중점을 두고 개발되었습니다.
텍스트 분석은 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 비즈니스 인텔리전스(Business Intelligence)나 예측 분석 등의 분석 작업을 주로 수행합니다.
텍스트 분석은 비정형 데이터인 텍스트를 분석하는 것입니다.
머신러닝 알고리즘은 숫자형의 피처 기반 데이터만 입력받을 수 있기 때문에 텍스트를 피처 형태로 추출하고 추출된 피첱에서 의미있는 값을 부여하는 것이 중요합니다.
이렇게 변환하는 것을 피처 벡터화(Feature Vectorization) 또는 피처 추출(Feature Extraction)이라고 합니다.
대표적으로 텍스트를 피처 벡터화하는 방법으로 BOW(Bag of Words)와 Word2Vec 방법이 있습니다.
텍스트 분석 수행 프로세스
1. 텍스트 전처리(텍스트 사전 준비 작업)
2. 피처 벡터화/추출
3. ML 모델 수립 및 학습/예측/평가
텍스트 전처리(텍스트 사전 준비 작업)
⊙ 클렌징 : 텍스트에서 분석에 방해가 되는 불필요한 문자, 기호 등을 사전에 제거하는 작업.
예를들어 HTML, XML 태그나 특정 기호 등을 사전에 제거.
⊙ 텍스트 토큰화 : 문서에서 문장을 분리하는 문장 토큰화와 문장에서 단어를 토큰으로 분리하는 단어 토큰화로 나뉩니다.
👉🏻 문장 토큰화
문장의 마침표(.), 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적.
또한 정규 표현식에 따른 문장 토큰화도 가능합니다.
from nltk import sent_tokenize
import nltk# 마침표, 개행 문자 등 데이터 세트 다운
nltk.download('punkt')결과

text_sample = 'I know he’s dead! Don’t you think I know that? I can still like him, though, can’t I? Just because somebody’s dead, you don’t just stop liking them, for God’s sake―especially if they were about a thousand times nicer than the people you know that’re alive and all.” Old Phoebe didn’t say anything. When she can’t think of anything to say, she doesn’t say a goddam word. “Anyway, I like it now,” I said. “I mean right now. Sitting here with you and just chewing the fat and horsing―”'
sentences = sent_tokenize(text=text_sample)
print(type(sentences), len(sentences))
print(sentences)결과

sent_tokenize()가 반환하는 것은 각각의 문장으로 구성된 list 객체입니다.
👉🏻 단어 토큰화
기본적으로 단어를 토큰화할 때는 공백, 콤마(,), 마침표(.), 개행문자 등으로 단어를 분리하지만, 정규 표현식을 이용해 다양한 유형으로 토큰화를 수행할 수 있습니다.
from nltk import word_tokenize
sentence = 'I mean right now. Sitting here with you and just chewing the fat and horsing'
words = word_tokenize(sentence)
print(type(words), len(words))
print(words)결과

👉🏻 문장 토큰화 후 단어 토큰화
문서를 먼저 문장으로 나누고 개별 문장을 다시 언어로 토큰화하는 함수 생성.
from nltk import sent_tokenize, word_tokenize
# 여러 개의 문장으로 된 입력 데이터를 문장별로 단어 토큰화하게 만드는 함수 생성
def tokenize_text(text):
# 문장별로 분리 토큰
sentences = sent_tokenize(text)
# 분리된 문장별 단어 토큰화
word_tokens = [word_tokenize(sentence) for sentence in sentences]
return word_tokens
text_sample = 'I know he’s dead! Don’t you think I know that? I can still like him, though, can’t I? Just because somebody’s dead, you don’t just stop liking them, for God’s sake―especially if they were about a thousand times nicer than the people you know that’re alive and all.” Old Phoebe didn’t say anything. When she can’t think of anything to say, she doesn’t say a goddam word. “Anyway, I like it now,” I said. “I mean right now. Sitting here with you and just chewing the fat and horsing―”'
# 여러 문장에 대해 문장별 단어 토큰화 수행
word_tokens = tokenize_text(text_sample)
print(type(word_tokens), len(word_tokens))
print(word_tokens)결과
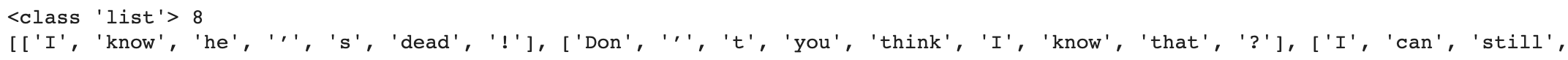
8개의 문장으로 이루어진 문서이므로 8개의 리스트 객체를 내포하는 리스트를 반환합니다.
하지만 이처럼 문장을 단어별로 하나씩 토큰화하면 문맥적인 의미가 무시됩니다.
그런 문제를 해결해보고자 도입된 것이 n-gram입니다. n-gram은 연속된 n개의 단어를 하나의 토큰화 단위로 분리해 내는 것입니다.
n개 단어 크기 윈도우를 만들어 문장의 처음부터 오른쪽으로 움직이면서 토큰화를 수행합니다.
⊙ 스톱 워드 제거 : 분석에 큰 의미가 없는 단어를 제거하는 방법
👉🏻 스톱 워드 제거
import nltk
nltk.download('stopwords')print('영어 stop words 개수 : ', len(nltk.corpus.stopwords.words('english')))
print(nltk.corpus.stopwords.words('english')[:20])결과

영어에 stopwords(불용어)로 등록된 개수는 179개 이며 토큰화에서 생성한 단어에서 불용어를 제거해 의미있는 단어만 추출해보겠습니다.
import nltk
stopwords = nltk.corpus.stopwords.words('english')
all_tokens=[]
# 토큰화 예제에서 문자별로 얻은 word_tokens list에 대해 스톱 워드를 제거하는 반복문
for sentences in word_tokens:
filtered_words=[]
# 개별 문장별로 토큰화된 문장 list에 대해 스톱 워드를 제거하는 반복문
for word in sentences:
# 소문자로 모두 변환합니다.
word=word.lower()
# 토큰화된 개별 단어가 스톱워드의 단어에 포함되지 않으면 word_tokens에 추가
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)결과
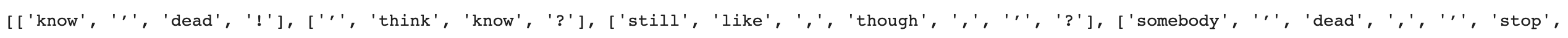
I, he 등 불용어가 필터링을 통해 제거되었습니다.
한글 stopwords(불용어) 제거
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
sentence_example = '내가 할 일은 아이들이 절벽으로 떨어질 것 같으면, 재빨리 붙잡아주는 거야. 애들이란 앞뒤 생각 없이 마구 달리는 법이니까 말이야. 그럴 때 어딘가에서 내가 나타나서는 꼬마가 떨어지지 않도록 붙잡아주는 거지. 온종일 그 일만 하는 거야. 말하자면 호밀밭의 파수꾼이 되고 싶다고나 할까.'
stop_words = '이 있 하 것 들 그 되 수 이 보 않 없 나 사람 주 아니 등 같 우리 때 년 가 한 지 대하 오 말 일 그렇 위하 때문 그것 두 말하 알 그러나 받 못하 일 그런 또 문제 더 사회 많 그리고 좋 크 따르 중 나오 가지 씨 시키 만들 지금 생각하 그러 속 하나 집 살 모르 적 월 데 자신 안 어떤 내 경우 명 생각 시간 그녀 다시 이런 앞 보이 번 나 다른 어떻 여자 개 전 들 사실 이렇 점 싶 말 정도 좀 원 잘 통하 소리 놓'
stop_words = stop_words.split(' ')
word_tokens = word_tokenize(sentence_example)
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
print(word_tokens)
print(result)결과

⊙ Stemming, Lemmatization : 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것.
👉🏻 Stemming
원형 단어로 변환 시 일반적인 방법을 적용하거나 더 단순화된 방법을 적용해 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있습니다. Stemming은 Lemmatization 보다 더 단순하게 원형 단어를 찾아줍니다.
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('working'), stemmer.stem('works'), stemmer.stem('worked'))
print(stemmer.stem('amusing'), stemmer.stem('amuses'), stemmer.stem('amused'))
print(stemmer.stem('happier'), stemmer.stem('happiest'))
print(stemmer.stem('fancier'), stemmer.stem('fanciest'))결과

work는 진행형(working), 3인칭 단수(works), 과거형(worked) 모두 기본 단어인 work에 ing, s, ed가 붙는 단순한 변화이므로 원형인 work를 인식합니다.
그러나 amuse는 amus에 ing, s, ed가 붙으므로 정확한 단어인 amuse가 아닌 amus를 원형 단어로 인식합니다.
형용사인 happy, fancy의 경우도 비교형, 최상급형으로 변형된 단어의 정확한 원형을 찾지 못하고 원형 단어에서 철자가 다른 어근 단어로 인식하는 경우가 발생합니다.
Stemming은 원형을 정확하지 찾지 못한다는 단점이 있습니다.
👉🏻 Lemmatization
Stemming와 동일하게 단어의 원형을 찾는 기능이지만 보다 정확한 원형 단어 추출을 위해 단어의 '품사'를 입력해줘야 합니다.
lemmatitiza()의 파라미터로 동사의 경우 'v', 형용사의 경우 'a'를 입력합니다.
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('wordnet')
lemma=WordNetLemmatizer()
print(lemma.lemmatize('amusing', 'v'), lemma.lemmatize('amuses', 'v'), lemma.lemmatize('amused', 'v'))
print(lemma.lemmatize('happier', 'a'), lemma.lemmatize('happiest', 'a'))
print(lemma.lemmatize('fancier', 'a'), lemma.lemmatize('fanciest', 'a'))결과

Stemmer보다 정확하게 원형 단어를 추출해줌을 알 수 있습니다.
참고
www.upgrad.com/blog/what-is-text-mining-techniques-and-applications/
'Deep Learning > 이론' 카테고리의 다른 글
| 정보 검색 개념 (0) | 2021.02.18 |
|---|---|
| BOW(Bag of Words) (0) | 2020.12.17 |
| PCA 분석 (0) | 2020.12.02 |
| Word2vec (0) | 2020.11.29 |
| Word Embedding 이론 (0) | 2020.11.25 |



