

Patrick's 데이터 세상
Python 데이터 분석 - 통계 검정 본문
참고 파일 : 06.intro-statistics.ipynb
모든 데이터는 숫자로 분석해야한다.
text 분석은 빈도수 Bow(Back Of Words)로 분석.
분포를 알면 분포로부터 확률을 가져올 수 있다.
우리가 다루는 데이터는 표본이고 표본은 모집단과 연관되어 있다.
표본을 분석해서 모집단을 예측, 추정하는 과정.
* 현재는 데이터가 너무 많기 때문에 p-value가 무조건 낮아진다.
p-value가 0.5가 아니다 0.005로 보는게 맞다는 의견이 많다.
* stochastic
pick을 조정해서 뽑다보면 정규분포에 근접하는 방법
모집단과 통계량
모집단
조사 대상 데이터 전체
표본
조사 대상의 일부 데이터
기초 통계량 - 평균, 분산, 표준편차
▪ 평균
– 전체 데이터의 합을 데이터의 개수로 나눈 값
– 편차와 분포를 반영하지 못하는 문제
▪ 중앙값(median)
– 모든 데이터를 크기 순서로 정렬했을 때 가운데 위치한 값
– 정도의 차이는 있으나 평균과 마찬가지로 분포를 반영하지 못하는 문제
▪ 분산
– 각 데이터와 평균 사이의 편차를 제곱한 값의 평균
– 편차에 음의 값이 존재하고 편차의 평균이 0이 되므로 제곱의 평균 사용
▪ 표준편차
– 분산의 제곱근을 구한 값
⊙ 기초 통계량 관련 함수
import numpy as np
import scipy as sp # 과학 계산용 파이썬 모듈
import scipy.stats as stats
import pandas as pdx = [1, 13, 51, 7, 10, 22, 94, 64, 38]print(len(x)) # 갯수
print(np.mean(x)) # 평균
print(np.var(x)) # 분산
print(np.std(x)) # 표준 편차
print(np.max(x)) # 최댓값
print(np.min(x)) # 최솟값
print(np.median(x)) # 중앙값
print(np.percentile(x, 25)) # 1사분위 수
print(np.percentile(x, 50)) # 2사분위 수
print(np.percentile(x, 75)) # 3사분위 수결과

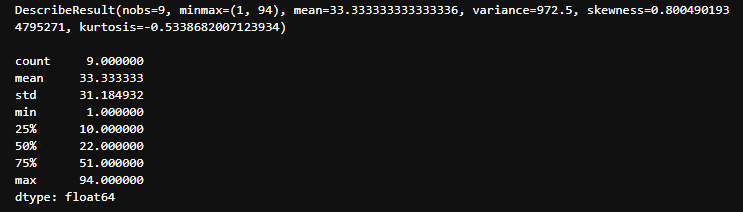
⊙ 기초 통계량 관련 함수2
print(sp.stats.describe(x))
print()
s = pd.Series(x)
print(s.describe())결과
⊙ 표준 정규 분포

데이터를 다룰때는 정규분포를 따르는지 여부에 따라 분석함.
▪ -(무한대) ~ +(무한대) 까지의 모든
수치 데이터로 구성
▪ 데이터의 평균 값을 기준으로 좌/우
대칭형으로 분포 되어 있는 형태
▪ 상대도수는 수치에 따라 다르다
– 무한대의 데이터에 대해 도수
측정은 불가능하므로 상대도수를
사용
– 단일 데이터가 아닌 범위 데이터에 대한 상대도수(비율)을 주로 사용
▪ 평균값은 0, 표준편차는 1
▪ 표준편차의 1배 범위의 상대도수는 0.6826 (대략 70%), 2배 범위의 상대도수는
0.9544 (대략 95%)
일반적으로 1.96배를 95%로 사용(관용적으로 많이 사용하는 임계치)
⊙ 일반 정규 분포
▪ 표준정규분포의 모든 데이터에 일정한 수(표준편차)를 곱한 후 일정한
수(평균)를 더한 데이터 분포

▪ 일반정규분포 데이터의 분포 특성

▪ 일반정규분포 데이터를 표준정규분포로 변환

⊙ 일반 정규 분포
▪ 표준정규분포 모집단에서 얻은 n개의 데이터에 대해 각각 제곱한 합으로
계산되는 통계량 V는 자유도 n인 카이제곱분포를 한다

▪ 자유도에 따른 각 데이터와 상대도수를 작성한 카이제곱표 제공

⊙ t 분포
▪ 표본평균 , 표본표준편차 를 이용한 통계량 t 도출

▪ T분포 히스토그램

▪ 정규모집단에서 추출된 표본 데이터의 통계량으로 모평균 추정 가능
⊙ 상관 관계 분석
▪ 두 변수간에 선형적 관계가 있는 지 분석하는 방법.
어떤 하나의 데이터가 변할때 다른 데이터도 같이 변하는 정도.
▪ 두 변수는 서로 독립적인 관계로부터 서로 상관된 관계일 수 있으며 이때 두 변수간의 관계의 강도를 상관관계라 한다.
▪ 상관분석에서는 상관관계의 정도를 나타내는 단위로 상관계수 r을 사용한다
– 상관관계의 정도를 파악하는 상관계수는 두 변수간의 연관된 정도를 나타낼 뿐 인과관계를 설명하는 것은 아니다.
– 두 변수 사이에 원인과 결과의 인과관계가 있는지에 대한 것은 회귀분석을 통해 인과관계의 방향, 정도와 수학적 모델을 확인해 볼 수 있다.
– 0 < r ≤ +1 이면 양의 상관, -1 ≤ r < 0 이면 음의 상관, r = 0이면 무상관 이라고 한다.
– 0인 경우 상관이 없다는 것이 아니라 선형의 상관관계가 아니라는 것이다.
▪ 상관 관계가 있다고 인과 관계가 있는 것은 아니다.

⊙ 상관계수
▪ 두 확률 변수 사이의 관계를 파악하는 방식
– 일반적으로 피어슨 상관계수를 의미
!pip install scikit-learnfrom sklearn.datasets import load_iris
import pandas as pdsklearn -> scikit-learn의 다른 이름
Python ML(Machine Learning) Package의 대표적인 모듈
iris = load_iris() # 붓꽃 품종 분류 데이터 로딩iris.keys()결과

key : data 설명변수
target 목적변수
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df['species'] = iris.target
correlation_matrix = iris_df.corr() # 상관계수 계산
correlation_matrix결과
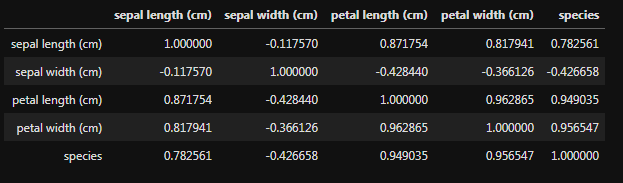
절대 값이 .3 이상이면 상관관계가 있다.
꽃잎 너비, 길이
꽃받침 너비, 길이
품종 데이터
* 꽃잎과 꽃받침을 통해 품종을 알아 낼 수 있는가.
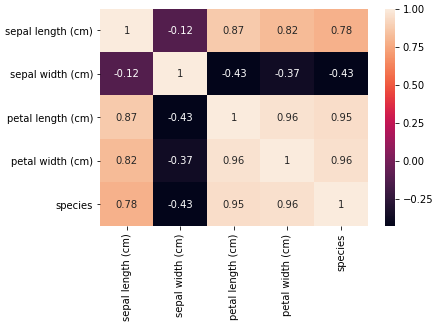
* 상관계수 시각화
import matplotlib.pyplot as plt
import seaborn as sns
ax = sns.heatmap(correlation_matrix, annot=True)
ylim = ax.get_ylim() # y축 범위
ax.set_ylim(ylim[0]+0.5, ylim[1]-0.5)
plt.show()결과
▪ 스피어만 상관계수
– 상관계수를 계산할 두 데이터의 실제 값 대신 두 값의 순위를 사용해 상관계수 비교
– 이산형 데이터 및 순서형 데이터 적용 가능
– 예)국어점수-영어점수 관계는 피어슨 / 국어석차-영어석차는 스피어만
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = x ** 2
print(sp.stats.pearsonr(x, y))
print(sp.stats.spearmanr(x, y))결과

▪ 켄달의 순위 상관계수
– (X, Y) 형태의 순서쌍 데이터에 대해 x1 < x2 에 대해 y1 < y2가
성립하면 concordant, 성립하지 않으면 discordant라고 정의
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = x ** 2
print(sp.stats.pearsonr(x, y))
print(sp.stats.kendalltau(x, y))결과

* 상관계수 시각화
▪ 상관계수 검정
– corr.test() 함수를 사용해서 상관 계수의 유의성을 판단할 수 있다
– 귀무 가설은 상관계수가 0인 가설
corr_values, pval = sp.stats.pearsonr(iris_df.iloc[:, 0], iris_df.iloc[:, 4])
print(corr_values)
print(format(pval, '.55f') )결과

rho, pval = sp.stats.pearsonr(iris_df.iloc[:, 0], iris_df.iloc[:, 4])
print(rho)
print(pval)결과

tau, pval = sp.stats.kendalltau(iris_df.iloc[:, 0], iris_df.iloc[:, 4])
print(rho)
print(pval)결과

귀무가설 : 관심있는 것의 반대 가설(상관계수가 0이다.)
1. 귀무가설을 정한다.
2. 표본의 상관계수(검정통계량) 계산(예 : 상관계수 0.7)
3. 귀무가설 하에 상관계수(예: 0.7)이 나올 수 있는 확률(p-value) 계산(예: 0.5)
모집단에는 상관 관계가 없다.
일부를 뽑아서 0.7이 나오고 상관계수가 0.7이 나올 확률이 0.5이면 귀무가설을 기각할 수 없다.
p-value값이 기각 임계치(0.5)보다 낮아야 기각.
상관관계가 있다.
⊙ 이항 검정
▪ 이항 분포를 이용하여 Bernoulli 분포 모수 μ에 대한 가설을 조사하는 검정 방법.
▪ SciPy stats 서브패키지의 binom_test 명령으로 이항 검정의 유의 확률을 계산.
▪ 디폴트 귀무 가설은 μ=0.5
N = 10 # 시행횟수
mu_0 = 0.5 # 평균
np.random.seed(0)
x = sp.stats.bernoulli(mu_0).rvs(N) # 난수 발생(rvs: Random Value Selection)
n = np.count_nonzero(x)
print(n)결과
7
p_value = sp.stats.binom_test(n, N)
print(p_value)결과
0.3437499999999999
귀무가설(동전 앞면이 10번 중 5번 나온다.) 0.5에서 0.7이 나오면 확률이 34%면 믿을만하지만 애매하다.
예) 불량률, 동전 앞면이 나올 확률, 등
⊙ 카이제곱 검정
▪ 두 범주형 데이터(성별, 운동량(많음, 적음))의 상관 관계
▪ 범주형 확률 분포의 모수 μ에 대한 가설을 조사하는 검정 방법
▪ 원래 범주형 값 k가 나와야 할 횟수의 기댓값 mk와 실제 나온 횟수 xk의 차이를 이용하여 검정 통계량 도출

▪ 어떤 범주형 확률변수 X가 다른 범주형 확률변수 Y와 독립 또는 상관관계 존재 여부도 검증
* 독립성 검정
obs = np.array([[5, 15], [10, 20]]) # 행 : 남,여 열 : 자연사, 사고사
chi2, p_value, dof, expected = sp.stats.chi2_contingency(obs)
print(chi2, p_value)결과

귀무가설 : 남여 별 자연사, 사고사 여부는 독립적이다. 상관이 없다.
chi2 : 카이제곱 값(검정 통계량), dof : 속성 값의 종류의 갯수, expected : 기대 값
귀무가설 채택, 남여 별 자연사, 사고사 여부는 상관이 없다.
obs = np.array([[4, 16, 20], [23, 18, 19]])
chi2, p_value, dof, expected = sp.stats.chi2_contingency(obs)
print(chi2, p_value)결과

⊙ T 검정
▪ 정규 분포의 표본에 대해 기댓값을 조사하는 검정방법
▪ 검정 통계량으로 t-통계량 사용 t 분포로부터 유의 확률 계산
▪ 연속 확률 분포 및 표본 분포 정규 분포와 유사한 분포
▪ 정규분포는 표본의 데이터 수가 많아야 신뢰도가 향상되는 단점
▪ 예측 범위가 넓은 분포를 사용해서 정규 분포의 문제점에 대응
– 주로 30개 미만의 표본에 대해 적용
'Data Analysis > EDA' 카테고리의 다른 글
| Python 데이터 분석 - 통계분석 (0) | 2020.06.24 |
|---|---|
| Python 데이터 분석 - 통계분석 기초 (0) | 2020.06.24 |
| Python 데이터 분석 - 탐색적 자료 분석 EDA (NumPy를 활용한 그래프, 산점도) (0) | 2020.06.24 |
| Python 데이터 분석 - 지도 시각화(EDA) (2) | 2020.06.24 |
| Python 데이터 분석 - 탐색적 자료 분석 EDA (Na 데이터 처리, Seaborn 그래프) (0) | 2020.06.24 |



