
Patrick's 데이터 세상
Python 데이터 분석 - 통계분석 본문
환경설정
source activate pyshpark
jupyter lab --notebook-dir=/Users/sunghwanpark/Desktop/shpark/Development/Python/GottAcademy/AcademyPractice/workspace/nb-workspace
◎ NumPy를 활용한 통계 분석
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
- data-files/brain-size.csv 파일의 데이터를 읽어서 DataFrame에 저장하세요
(각 행의 데이터 구분자는 ;이며 결측치는 "."으로 저장되어 있는 점을 고려하세요 )
data = pd.read_csv('data-files/brain-size.csv',
sep=';',
na_values=".") # FSIQ : Full Scale IQ
# VIQ : Verbal IQ
# PIQ : Performance IQ
- 데이터 정보 보기
data.info()
data.head()결과

- 데이터 프레임의 첫 번째 컬럼은 순번 데이터입니다. 이 컬럼을 제거하세요
data.drop(data.columns[0], axis=1, inplace=True)data.head()결과

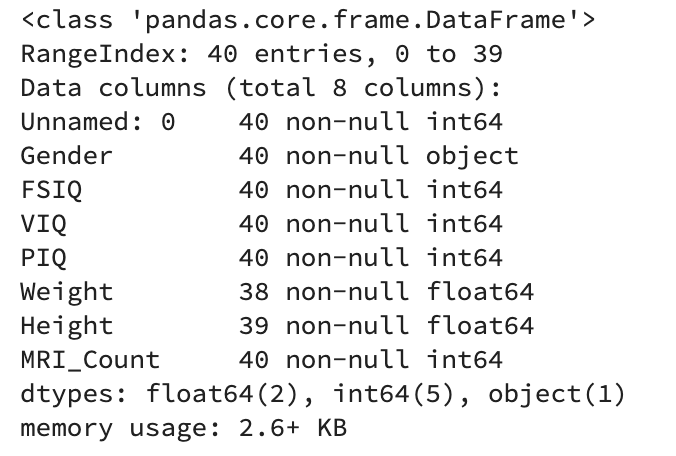
- 성별을 기준으로 데이터를 Group으로 묶어서 (groupby 사용) 변수에 저장하세요 (변수이름 : groupby_gender)
groupby_gender = data.groupby('Gender')groupby_gender.head()결과

- 위에서 저장한 데이터를 사용해서 성별 VIQ의 평균을 출력하세요
for gender, value in groupby_gender['VIQ']:
print((gender, value.mean()))결과

- 성별을 기준으로 모든 컬럼의 평균을 출력하세요
groupby_gender.mean()결과
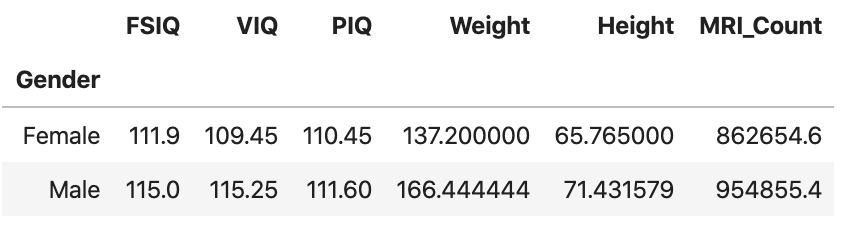
- 성별을 기준으로 각 컬럼의 데이터를 boxplot으로 시각화 하세요
groupby_gender.boxplot(figsize=(15, 5))
plt.show()결과
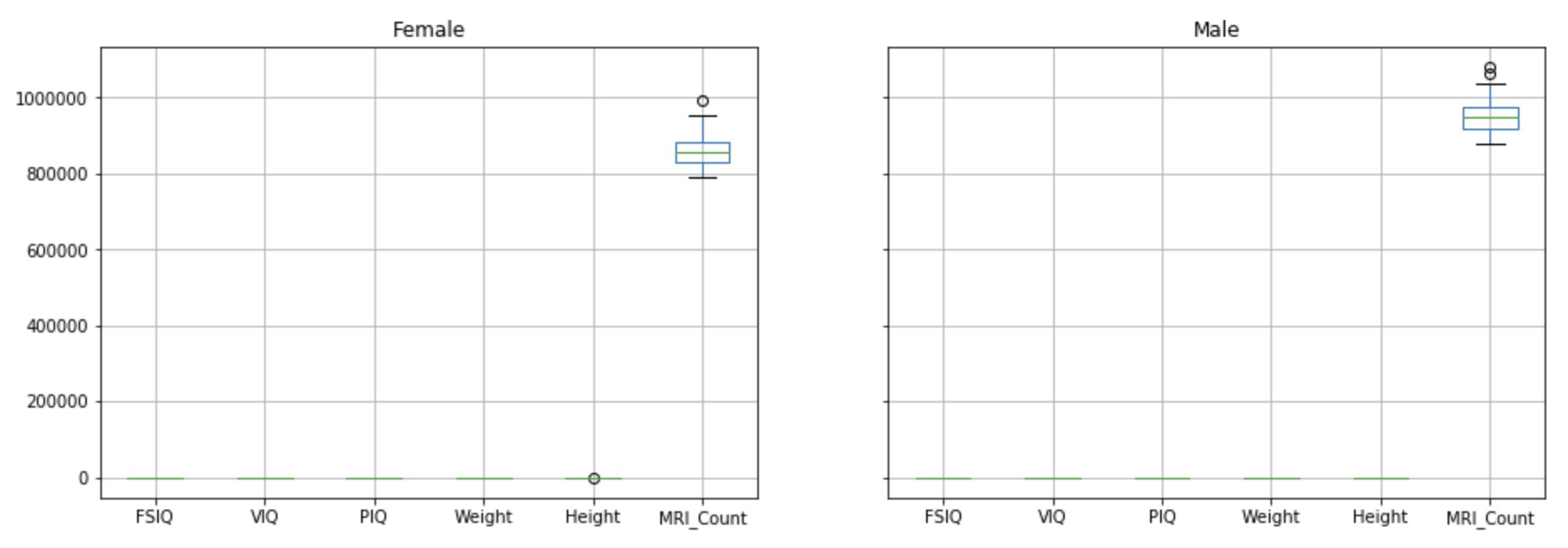
- 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 Weight, Height, MRI_Count 컬럼에 대해 비교 산점도를 출력하세요 (pairplot 사용)
plt.figure(figsize=(10, 5))
sns.pairplot(data[["Weight", "Height", "MRI_Count"]])
plt.show()결과
- 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 PIQ, VIQ, FSIQ 컬럼에 대해 비교 산점도를 출력하세요 (pairplot 사용)
plt.figure(figsize=(10, 5))
sns.pairplot(data[["PIQ", "VIQ", "FSIQ"]])
plt.show()결과

- 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 PIQ, VIQ, FSIQ 컬럼에 대해 비교 산점도를 성별로 구분해서 출력하세요 (pairplot 사용)
plt.figure(figsize=(10, 5))
sns.pairplot(data[["PIQ", "VIQ", "FSIQ", "Gender"]], hue="Gender")
plt.show()결과
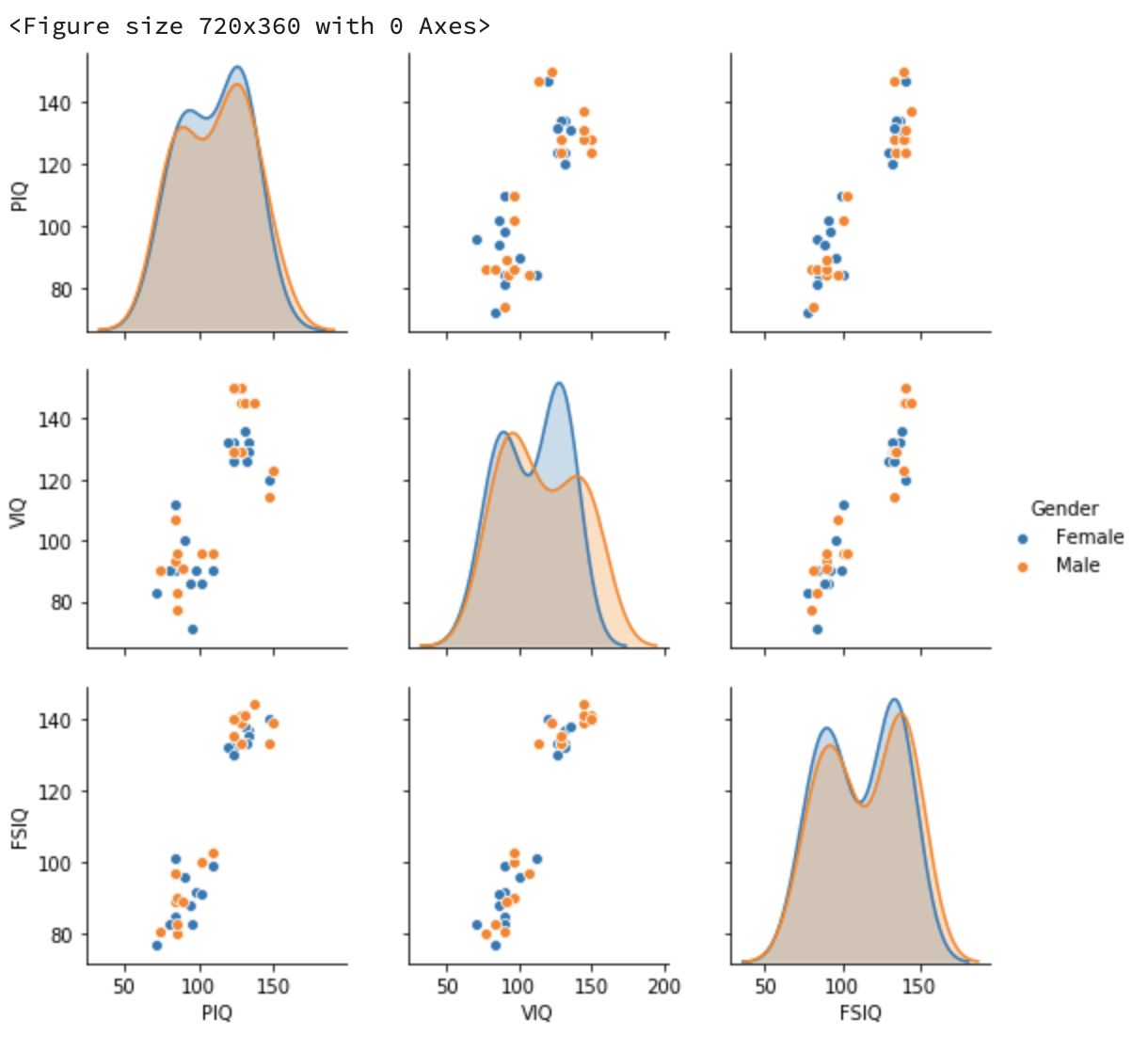
실습 예제
1. 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 각 컬럼별 상관 계수를 출력하세요
data.corr()결과

2. 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 각 컬럼별 상관 계수를 HeatMap으로 출력하세요
ax = sns.heatmap(data.corr(), annot=True)
ylim = ax.get_ylim()
ax.set_ylim(ylim[0] + 0.5, ylim[1] - 0.5)
plt.show()결과

3. 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 FSIQ와 VIQ 컬럼의 Pearson 상관계수와 p-value를 출력하세요 (두 컬럼의 상관성의 유의미성을 평가해 보세요)
from scipy import statspr, pvalue = stats.pearsonr(data["FSIQ"], data["VIQ"])
print(format(pr, '.60f'))
print(format(pvalue, '.60f'))결과

4. 원본 데이터 (data 변수에 저장된 데이터)를 사용해서 VIQ의 평균을 출력하세요
np.mean(data["VIQ"])결과
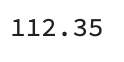
5. 위에서 출력한 VIQ의 평균으로 볼때 이 표본으로 대표되는 모집단의 VIQ 평균이 100보다 높다고 할 수 있는지 검정하세요
stats.ttest_1samp(data['VIQ'], popmean=100)결과
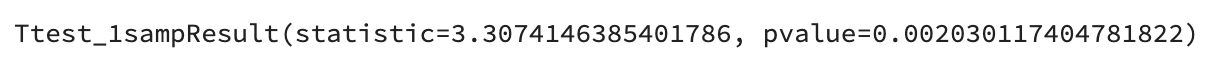
6. 여성과 남성의 VIQ를 뽑아서 각각 변수에 저장하고 평균을 출력하세요
print("Female : %f / Male : %f" % (data[data["Gender"] == 'Female']["VIQ"].mean(),
data[data["Gender"] == 'Male']["VIQ"].mean()))결과

7. 위에서 출력한 평균 값으로 볼 때 남성 또는 여성의 VIQ가 다른 성별의 VIQ보다 더 높다고 할 수 있는지 검정하세요
stats.ttest_ind(data[data["Gender"] == 'Female']["VIQ"],
data[data["Gender"] == 'Male']["VIQ"])결과

8. 전체 관측치에 대해 FSIQ의 전체 평균과 PIQ의 전체 평균이 같다고 할 수 있는지 검정하세요 (각 개인별 변화 또는 차이를 고려하지 않음)
print(data["FSIQ"].mean(), data["PIQ"].mean())
stats.ttest_ind(data["FSIQ"], data["PIQ"])결과

9. 관측된 각 개인별로 FSIQ의 평균과 PIQ의 평균에 차이가 있는지 검정하세요 (각 개인별 변화 또는 차이를 고려함)
stats.ttest_rel(data["FSIQ"], data["PIQ"])결과

# FSIQ와 PIQ의 값의 차이를 출력하세요
data['FSIQ'] - data['PIQ']결과

...생략
10. FSIQ와 PIQ의 값의 차이의 평균을 0으로 볼 수 있는지 검정하세요
stats.ttest_1samp(data['FSIQ'] - data['PIQ'], popmean=0)결과

'Data Analysis > EDA' 카테고리의 다른 글
| Python 데이터 분석 - 통계분석 기초 (0) | 2020.06.24 |
|---|---|
| Python 데이터 분석 - 탐색적 자료 분석 EDA (NumPy를 활용한 그래프, 산점도) (0) | 2020.06.24 |
| Python 데이터 분석 - 통계 검정 (0) | 2020.06.24 |
| Python 데이터 분석 - 지도 시각화(EDA) (2) | 2020.06.24 |
| Python 데이터 분석 - 탐색적 자료 분석 EDA (Na 데이터 처리, Seaborn 그래프) (0) | 2020.06.24 |



